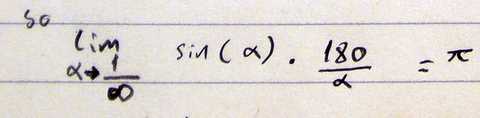c++
c++
Game Balyoz
svn checkout http://balyoz.googlecode.com/svn/trunk/ balyoz-read-only
http://code.google.com/p/balyoz/
Balyoz is a 3D shooter game having been written using OGRE engine.The aim is to provide a interesting
and enjoyable game play experience for the player and still in development.In order to achieve this purpose,
we have been using PyhsicX physic engine to provide a more realistic and unique game experience.Although
Balyoz is a classic 3D shooting game,it has also some different features then classic shooting games
offer and full of challenge even its underlying structure.The war plane will be flying over a terrain and be
capable of moving both X and Z direction.Besides, there will be different weapon options which makes
the game play more enjoyable.In Balyoz, other then enemy air units, there will be navy and ground units
which will be shooting to out plane as well.To destroy ground units, player have to use bombs with
the correct timing and position combination.I would like to give some information about the underlying
structure of the Balyoz game.
1.XML Based Definition
In order to achieve flexibility, unit definitions, weapons, levels, maps etc.. are defined XML files.
They are loaded either on game initialization stage or level lodging stage.It provides us a great
flexibility to alter the attributes, for example weapon attributes like speed, range or controller
type, or level attributes like the unit types in level and their positions, without changing even
one line code.It also prevents us to recompile the code for each time we change a attribute.
Let us have a look a example xml used in game.
<?xml version="1.0" ?> <weapons> <weapon> <name>bazooka</name> <mesh>cube.mesh</mesh> <reloadtime>500</reloadtime> <numofbullets> <capacity>1000</capacity> <initial>1</initial> <maximum>9</maximum> <minimum>1</minimum> <anglebetweenbullets>18</anglebetweenbullets> </numofbullets><bullet> <initialspeed>10</initialspeed> <maximumspeed>-100</maximumspeed> <power>100</power> <radius>10</radius> <effect>linear</effect> <lifetime>4.5</lifetime> <particles>Examples/Smoke</particles> <explosion>explosion</explosion> <controller>dummy</controller> </bullet> </weapon> </weapons> |
XML structure in terms of game is shown below,
Game.xml
|
Levels.xml ____
| |
Map.xml Terrain.xml
|
Units.xml
|
Weapons.xml
|
BulletController.xml
So,if it is needed to load a unit into the game, first units.xml file will be read and unit attribute
will be figured out from units.xml file.Then, weapon names related to that unit will be read from
units.xml file and with that reference, weapon attributes will be taken from weapon.xml file.
After that, the information about by which weapon controller it will be controlled will be read
from BulletController.xml file since for example guided missiles should be controlled in a
different way.As you can see, even controller types are defined in xml files and for sure, this
system provides a great flexibility when we want to add a new weapon to a unit, or a new
unit to a level.It is one of the most powerful feature of Balyoz in terms of design.
2.Controller Design
As a design decision, a main controller is implemented which is responsible to process
and update all the game events. Main game controller process the events via a event
queue it contains. Besides, there are some sub-controllers like Unit Controller or
Collision Controller which are responsible for creating related game events and adding
the main controller`s queue.So, before each frame is rendered, first all the controllers
are executed, produced related event and added to main controller`s event queue. Then
before rendering the frame (or after) this queue is processed by main controller and game
word is updated. Separating controlling behaviors to different controllers is also provides a
flexibility to implement control behavior and maintaining the code.Moreover, game core
talks to just main controller and does not need to know about sub-controllers.These design
decisions are shown by images below,


Balyoz is still in its early stage of development.I will be adding news about the progress of game.Beside, screenshots and videos will be added soon as well.